
Drift-Aware Fraud Detection — ML Lifecycle & Model Governance
Built an end-to-end ML system that detects data drift, evaluates model degradation, and governs retraining decisions.
Key Insight
"Link distributional drift to model degradation and automatically recover performance via retraining."
System Capabilities
- Real-time drift detection (KL divergence + PSI) with timeline tracking
- Automated retraining triggered by drift with cooldown constraints
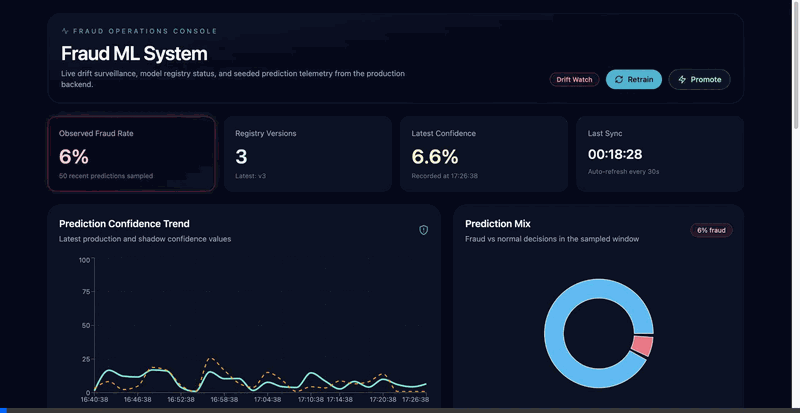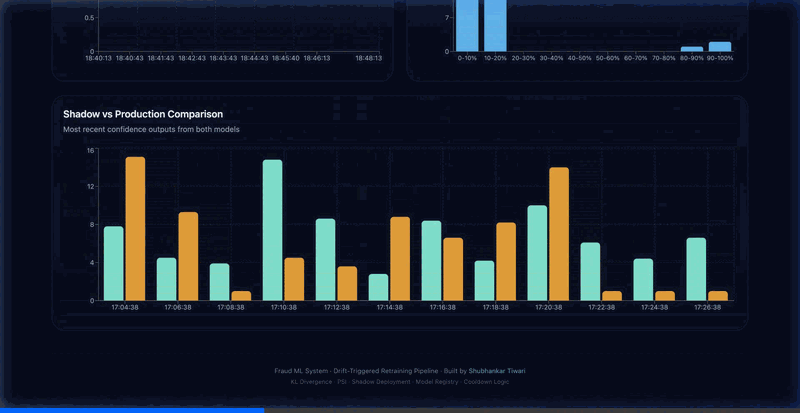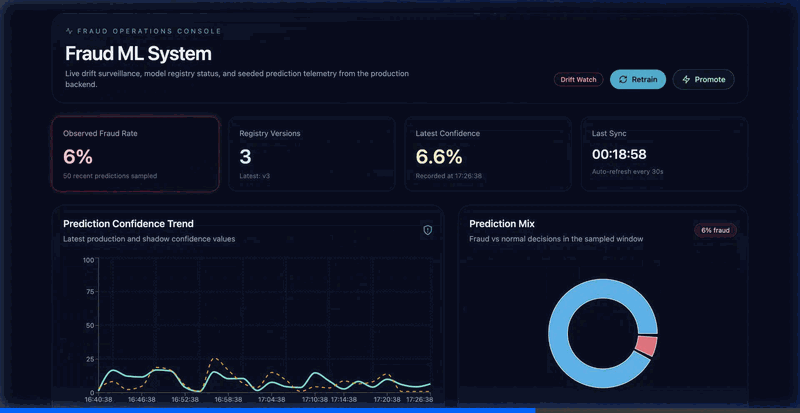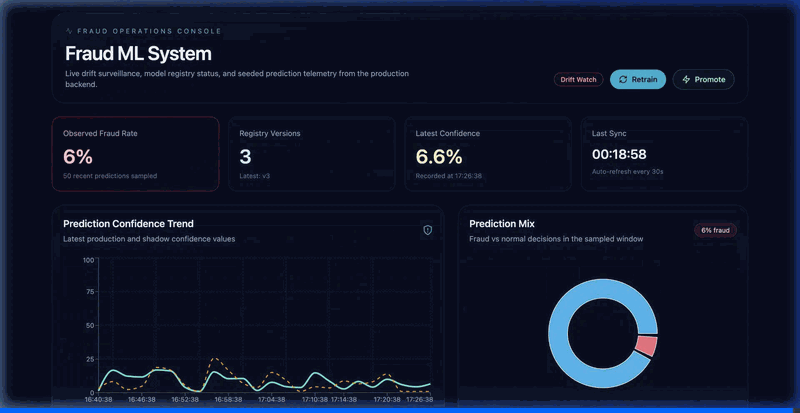
- Live observability dashboard with shadow vs. production comparison
Built an end-to-end ML system that detects data drift, evaluates model degradation, and governs retraining decisions.
The system continuously monitors feature distribution shifts and model performance, triggering retraining when degradation is detected. Candidate models are compared against production before deployment.
Includes: • Drift detection (statistical distribution monitoring) • Performance tracking (AUC-based evaluation) • Model comparison (production vs candidate) • Explicit decision loop (retrain / no_action) • CLI observability for drift history and decisions
Result: Ensures model reliability over time by linking data drift to automated lifecycle management.
Key Highlights
- Complete ML system loop: training → serving → drift monitoring → threshold trigger → cooldown gate → retraining → shadow deployment → promotion
- Real-time drift detection via KL divergence and PSI with persistent drift score timeline tracking distributional evolution over time
- Feature shift explanation surfaces the top shifted feature driving drift — interpretable ML system behavior, not just a number
- Retraining cooldown constraint prevents unstable loops under noisy drift signals — demonstrates real-world system constraints
- Shadow deployment architecture — every prediction scored by both production and candidate models simultaneously
- Failure-aware retraining pipeline with explicit SUCCESS/FAILED status tracking surfaced to the UI
- Versioned model registry with full provenance: trigger reason, drift score, top shifted feature, training timestamp, deployment status
- Live Next.js observability dashboard: drift timeline, confidence distribution histogram, prediction trends, fraud rate, system health, and shadow vs production comparison
- 10 API endpoints including /drift, /drift/history, /retrain/status, and /health for full system observability
Tech Stack
Backend
ML
Monitoring
Frontend
Challenges
- Extreme class imbalance (0.17% fraud) — required careful evaluation metrics (AUC-PR over accuracy) and SMOTE-based rebalancing
- Designing a shadow deployment loop that doesn't double latency — both models score every request but shadow results are non-blocking
- Drift threshold calibration — PSI > 0.2 and KL > 0.1 trigger retraining without causing false alarms on normal distribution shift
- Cooldown constraint design — preventing retraining instability under noisy drift without masking real distributional change
Key Learnings
- The model is the easy part — drift detection, cooldown constraints, failure handling, and registry governance are where production ML gets hard
- Feature shift explanation transforms a number into an actionable insight — interpretable drift is far more valuable than raw metrics
- Cooldown mechanisms are essential in any automated trigger system — without them, noisy signals cause runaway retraining loops
- Explicit promotion gates (shadow → production) prevent silent model degradation that auto-promotion would miss